
【はじめに】
- Pythonを覚えたので、実際に使ってみたい
- Pythonを使うと業務効率化が出来ると聞くけど、どんな業務に対して効率化を図れば良いか分からない
元営業だった私が、どんな業務に対して効率化できるのかお答えします。
本記事の内容
- Pythonで業務効率化を学びたい人がまずやって見てほしいことは「Webスクレイピング」
- スクレイピングをする上で注意すべきこと
- 元営業の私が、当時Pythonを知っていたらこんな業務を効率化します
【Pythonで業務効率化を学びたい人がまずやって見てほしいことは「Webスクレイピング」】
スクレイピングとは「Web上からデータを収集し、利用しやすく加工すること」です。
機械学習、マーケティング、サービス開発など幅広い領域で活用されています。
Pythonは、スクレイピング用のライブラリが豊富、かつプログラミング初心者でも比較的学習しやすい言語です。
【スクレイピングをする上で注意すべきこと】
スクレイピングするサイトの「robots.txt」を確認しましょう
「robots.txt」とは、クローラーに対してサイト内ページの巡回をブロックするのか、または許可するかどうかを記述して知らせるものです。
トップページにあたるURLに「/robots.txt」と続けると確認することができます。
「robots.txt」内の次の項目を確認しましょう
- User-agent:クロールを制御するクローラーを指定する項目です。
- Disallow(スクレイピングの拒否):クロールを制御するページを指定する項目です。
- Allow(スクレイピングの許可):Disallowで指定しているディレクトリ配下のサブディレクトリ・特定ページのクロールを指示する項目です。
つまり、スクレイピングをしても良いサイトなのかを確認することが重要です。
確認せずにスクレイピングをしてしまうと、利用規約違反に抵触してしまう可能性があります。
【元営業の私が、当時Pythonを知っていたらこんな業務を効率化します】
人材派遣会社の営業職でしたが、業務の一つに、競合他社の広告から掲載企業を検証するため、毎週他社サイトから求人広告を一件ずつエクセルにまとめるというものがありました。
一件ずつ詳細ページから情報を取得していましたが、午前中の業務時間全てを費やすほどでした。
もし、当時Pythonを知っていたら真っ先に効率化していると思います。
当時使用していた他社サイトは記事に掲載するには厳しいので、robots.txtを確認した上で、今回は「iタウンページ」を例に挙げて掲載情報をスクレイピングしてみようと思います。
※スクレイピングをするときはGoogle ColaboratoryやJupyter Labを使用して処理結果を一つずつ確認しながら行うことをオススメします。
スクレイピングに必要なライブラリをインポート
import requests
from bs4 import BeautifulSoup
- requestsはHTTPのGETリクエストで情報を取得するライブラリ
- BeautifulSoupはHTMLからデータを取得して解析するライブラリ
スクレイピングするURLを決める
今回は「さいたま市」をキーワードにiタウンページに掲載されている会社情報を取得していきます。
targetUrl = 'https://itp.ne.jp/keyword/?keyword=さいたま市'
- 検索エリアを変更したい場合、URL内のキーワード(パラメータ)を変更するだけでOKです。
- スクレイピングするサイトによってURLの構造は異なるので、事前にどの部分が重要なパラメータなのかを確認しましょう。
requestsで情報を取得する
res = requests.get(targetUrl)
- requests取得した情報を代入する変数は、
rやresとすることが多いです。
r(or res) = requests.get("URL")
# ( )内は直接URLを指定してもOK
BeautifulSoupでURLをHTML形式で情報を取得する
soup = BeautifulSoup(res.text, 'html.parser')
# soupの中身
>>
<!DOCTYPE doctype html>
<html data-n-head-ssr="">
<head>
</head>
<body>
----中略----
</body>
</html>
- HTML形式で取得した情報を代入する変数は
soupとすることが多いです。 - requestsで取得した情報「r」をHTML形式で取得するには次のように記述します。
soup = BeautifulSoup(r.text, 'html.parser')
会社名を取得する
Chromeを使用している場合、マウスを右クリックして「検証」を選択すると次のような画面が出てきます。


取得したい部分にカーソルを合わせると、HTMLの要素を確認することができます。
companyName = soup.find_all(class_="m-article-card__header__title__link")
# companyNameの中身
>>
[<a class="m-article-card__header__title__link" data-v-5bb65449="" href="https://itp.ne.jp/info/135075263100000899/" target="_blank">
株式会社建和
</a>,
<a class="m-article-card__header__title__link" data-v-5bb65449="" href="https://itp.ne.jp/info/133852752100000899/" target="_blank">
新宿さくらクリニック
</a>,
----中略----
<a class="m-article-card__header__title__link" data-v-5bb65449="" href="https://itp.ne.jp/info/118013339022430700/" target="_blank">
ラインファミリー株式会社
</a>,
<a class="m-article-card__header__title__link" data-v-5bb65449="" href="https://itp.ne.jp/info/510000000000076902/" target="_blank">
株式会社クラシアンさいたま支社
</a>]
- クラス名で取得したい要素を指定して、変数に次のように代入していきます。
変数 = soup.find_all(class_="クラス名")
最寄駅、電話番号、住所をまとめて取得する
それぞれ取得できるようなHTMLの構成になっていれば会社名の取得を同様の手順で問題ないです。
今回はテーブル構成の中に全てまとめられていて、クラス名が命名されていません。
そこで、まずはじめにまとめて情報を取得します。
jobInfo = soup.find_all(class_="m-article-card__lead__caption")
# jobInfoの中身
>>
[<p class="m-article-card__lead__caption" data-v-5bb65449="">
【最寄駅】大泉学園駅 / 武蔵関駅
</p>, <p class="m-article-card__lead__caption" data-v-5bb65449="">
【電話番号】(代) 03-3594-5121
</p>, <p class="m-article-card__lead__caption" data-v-5bb65449="">
【住所】東京都練馬区石神井台5丁目26-13
</p>, <p class="m-article-card__lead__caption" data-v-5bb65449="">
【最寄駅】新大久保駅 / 大久保駅
</p>, <p class="m-article-card__lead__caption" data-v-5bb65449="">
【電話番号】(代) 03-3364-6333
</p>, <p class="m-article-card__lead__caption" data-v-5bb65449="">
【住所】東京都新宿区百人町2丁目11-22
----中略----
【電話番号】 0120-558776
</p>, <p class="m-article-card__lead__caption" data-v-5bb65449="">
【住所】埼玉県さいたま市中央区上峰2丁目3-1
</p>, <p class="m-article-card__lead__caption" data-v-5bb65449="">
【電話番号】 0120-888700
</p>, <p class="m-article-card__lead__caption" data-v-5bb65449="">
【住所】埼玉県さいたま市北区吉野町2丁目200-1
</p>]
jobInfoから最寄駅、電話番号、住所それぞれに分ける
取得した情報では一つの会社に対して「最寄駅」、「電話番号」、「住所」の順番に情報が繰り返し含まれています。
それぞれ、2項目ずつ間隔を空けて情報を取得していきます。
station = jobInfo[0::3] #0番目から3個飛ばしで取得
telNo = jobInfo[1::3] #1番目から3個飛ばしで取得
address = jobInfo[2::3] #2番目から3個飛ばしで取得
- プログラミングの世界では配列の中の要素などの始まりは「0番目」から数えます。
- 配列のn番目からN個ずつ飛ばして取得していくには次のように記述します。
配列[n::N]
抽出した会社のうち15社分繰り返し、配列に追加していく
今回は抽出した会社のうち15社だけをサンプルにしていきます。
それぞれ抽出した、項目を「辞書型」の配列にしていきます。
i = 0
for each in companyName[:15]:
list = {
"companyName" : companyName[i].get_text(),
"station" : station[i].get_text(),
"telNo" : telNo[i].get_text(),
"address" : address[i].get_text()
}
#listを配列に追加していく
lists.append(list)
i += 1
# listsの中身
>>
[{'address': '\n 【住所】東京都新宿区百人町2丁目11-22\n ',
'companyName': '\n 新宿さくらクリニック\n ',
'station': '\n 【最寄駅】新大久保駅 / 大久保駅\n ',
'telNo': '\n 【電話番号】(代) 03-3364-6333\n '},
----中略----
{'address': '\n 【住所】埼玉県上尾市仲町1丁目7-25\n ',
'companyName': '\n くらや上尾店\n ',
'station': '\n 【最寄駅】上尾駅\n ',
'telNo': '\n 【電話番号】 0120-710998\n '}]
- 辞書型とは「キー」と「値」のペアでデータを保持するデータ構造です。
# 辞書型
{
"キー1" : "値1",
"キー2" : "値2",
・・・
"キーn" : "値n"
}
- 配列に値を追加していくには次のように記述します。
配列.append(値)
データ解析のためのライブラリ「pandas」をインポート
import pandas as pd
- pandasはデータ分析の過程において作業の大半を占める、データの前処理や探索的分析を柔軟かつ効率的に行うための高機能なデータ構造と各種ツールを提供しています。

DataFrame型にして、表にして見やすくする
companyLists = pd.DataFrame(lists)
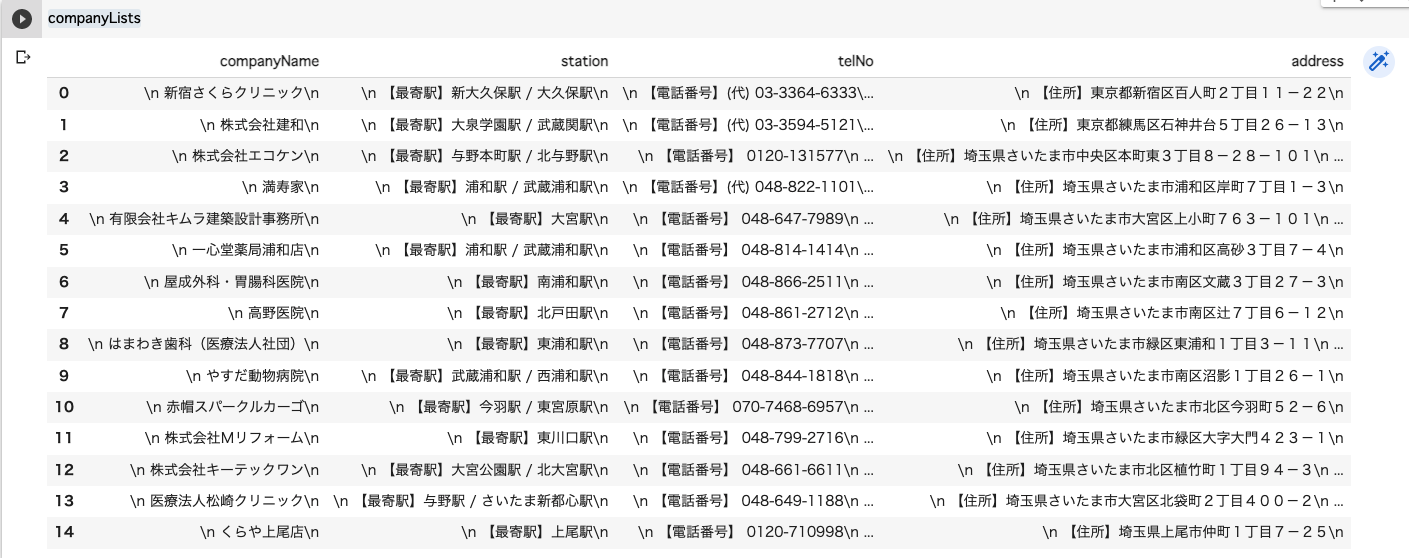
- 取得した辞書型のリストをDataFrame型にするには次のように記述します。
df = pd.DataFrame(リスト)
- DataFrame型を表す変数は
dfとすることが多いです。
CSV形式にして出力する
companyLists.to_csv("campanyLists.csv", encoding="cp932")
- DataFrame型をCSV形式で出力するには次のように記述します。
df.to_csv(“ファイル名.csv”, encoding=“文字コード”)
- AppleのNumbersで表示させる場合は、
encodingの記述は特に必要ありません。 - Excelで表示させる場合、
encodingにshift_jisかcp932を指定しないと文字化けすることがあります。 - 今回は改行コードがデータに含まれてしまっているため、
shift_jisだと文字化け解決出来ませんでした。
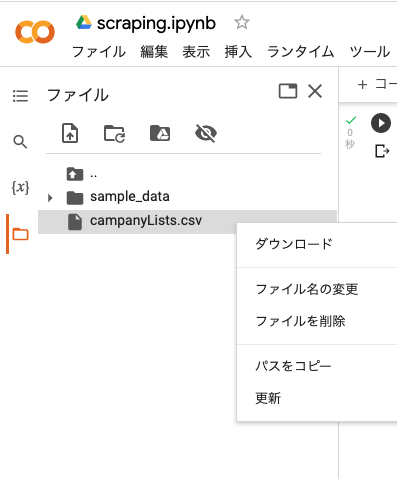
出力したCSVをダウンロードして表示させる
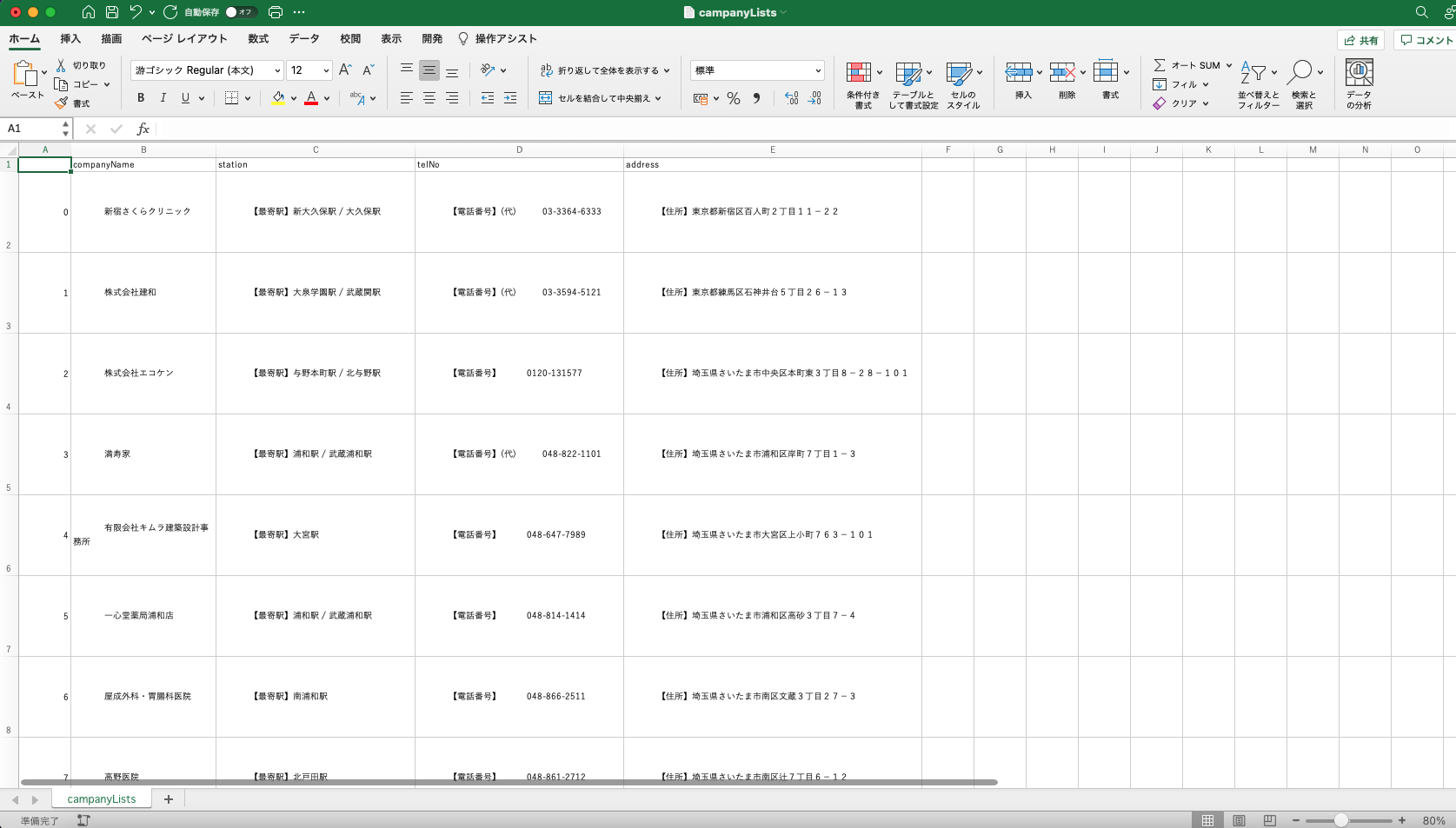
CSVの中身が問題なく出力されているか、確認します。
Google Colaboratoryを使用した場合、次のようにCSVが出力されるのでダウンロードします。
Excelで表示させると、問題なくリストになって出力されています。
【おわりに】
今回は、営業時代にPythonを知っていたらどんな業務を効率化するかということで、「Webスクレイピング」を挙げました。
サイトの利用規約を遵守した上であれば、Webスクレイピングは社内業務の効率化に対して大きな武器になります。
ビジネスサイドでプログラミングに強ければ、希少価値の高い人財にきっとなれるはずです。
是非、デジタル人財を目指していきましょう。


コメント