【はじめに】
Pythonライブラリの「Pandas」の中で、DataFrameを結合する方法はいくつかあります。
今回はその中でも「concat」、「merge」、「join」について、それぞれの違いに触れながら紹介していきます。
本記事の内容
- pandasのインポート
- csvファイルの読み込み
- 列を取得する
- DataFrameを結合する | concat()
- DataFrameを結合する | merge()
- DataFrameを結合する | join()
【pandasのインポート】
import pandas as pd
【csvファイルの読み込み】
「1920年から2015年までの全国の人口推移のデータ」を使用します。
df = pd.read_csv('data.csv', encoding='shift-jis')
df

私のGitHubに「data.csv」としてアップロードしてあるので、下記コマンドでダウンロードすれば簡単に準備できます。
$ curl https://raw.githubusercontent.com/nakachan-ing/python-references/master/Pandas/data.csv -O
【列を取得する】
例として、
- 「都道府県コード、都道府県名、元号、和暦(年)、西暦(年)」のデータ
- 「人口(総数)、人口(男)、人口(女)」のデータ
- 「大正、昭和(平成以外)」のデータ(平成以外)
- 「平成」のデータ
それぞれのデータに分けて、新しくデータフレームを作成します。
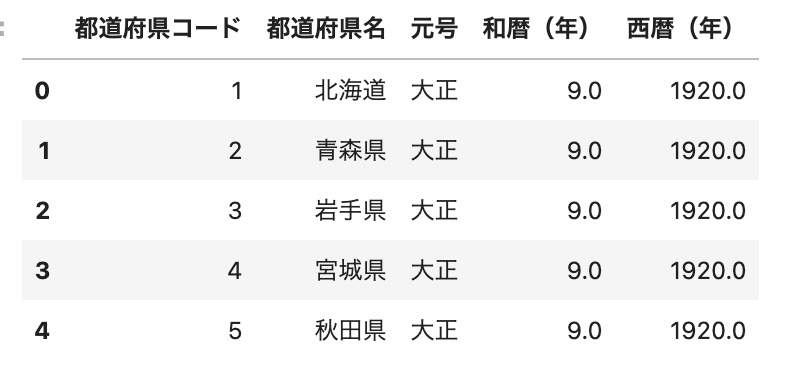
df_1 = df[['都道府県コード', '都道府県名', '元号', '和暦(年)','西暦(年)']]
df_1.head()
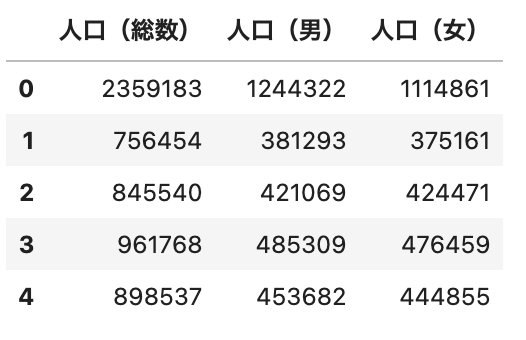
df_2 = df[['人口(総数)', '人口(男)', '人口(女)']]
df_2.head()
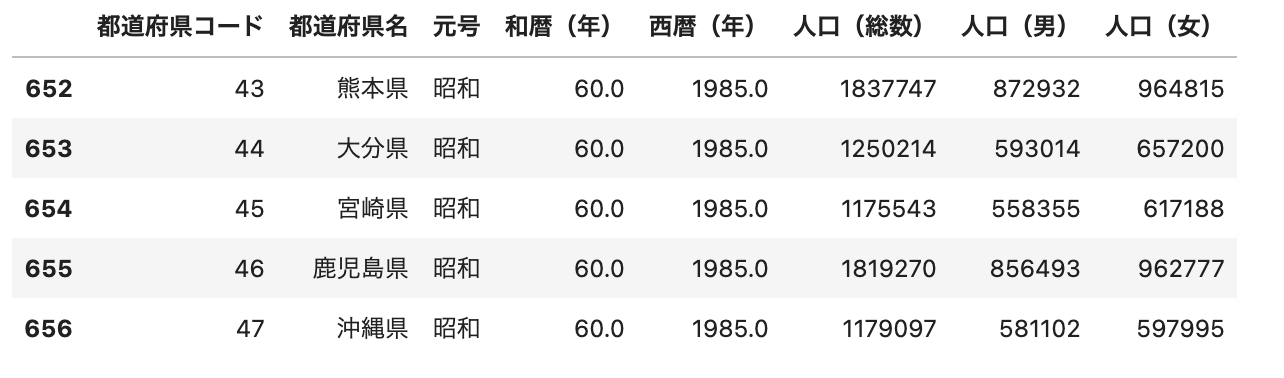
df_3 = df[df['元号']!='平成']
df_3.tail()
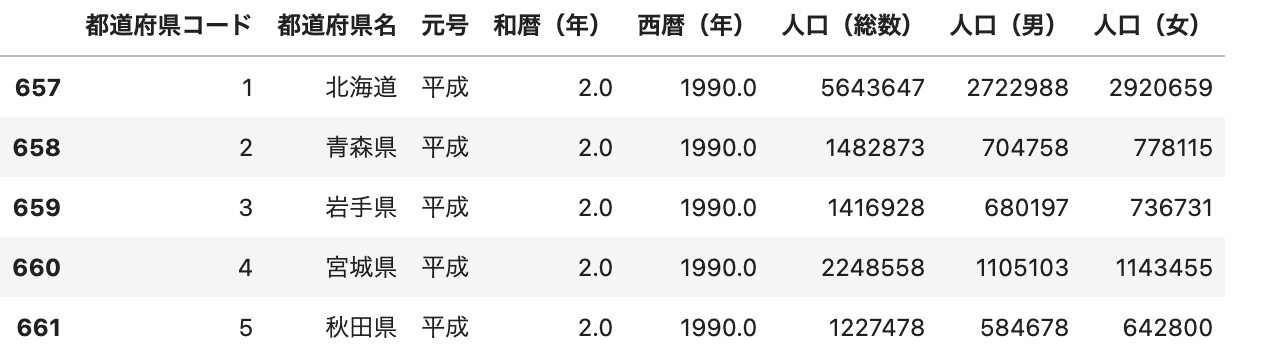
df_4 = df[df['元号']=='平成']
df_4.head()
ポイント
- 条件に合う列の値を取得する場合は、
DataFrame['カラム名']=='条件' - 条件以外の列の値を取得する場合は、
DataFrame['カラム名']!='条件' - 条件の値より大きい値を取得する場合は、
DataFrame['カラム名']>'条件' - 条件の値より小さい値を取得する場合は、
DataFrame['カラム名']<'条件'
【DataFrameを結合する | concat()】
pd.concat()関数では括弧内に結合したいpandas.DataFrameもしくはpandas.Seriesを角括弧[]で指定します。- 列方向に結合したい場合は、
axisオプションに「1」を指定します。
pd.concat([df_1, df_2], axis=1)
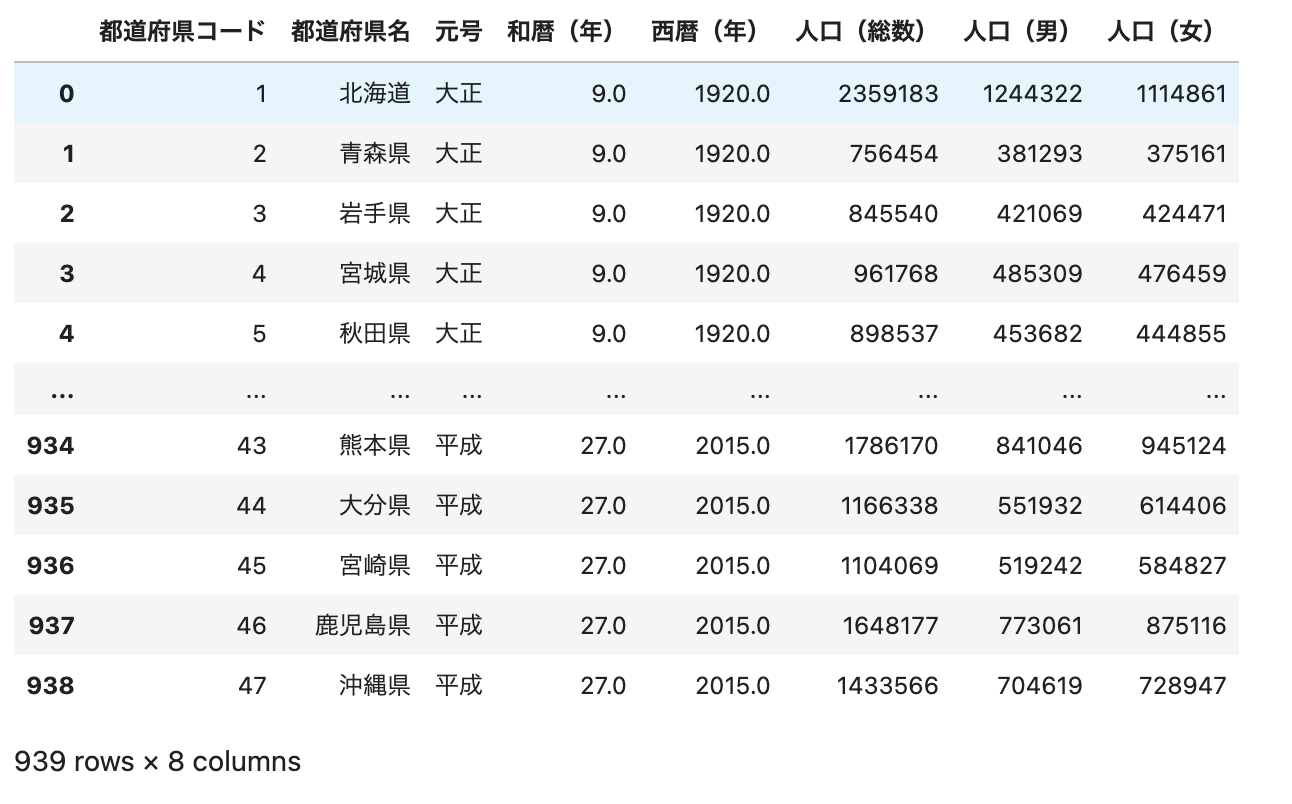
- 行方向に結合したい場合は、
axisオプションに「0」を指定します。
pd.concat([df_3, df_4], axis=0)
【DataFrameを結合する | merge()】
pd.merge()関数では括弧内に第一引数leftと第二引数rightに結合する2つのpandas.DataFrameを指定します。- 結合するDataFrameに重複した列が存在する場合に使用します。
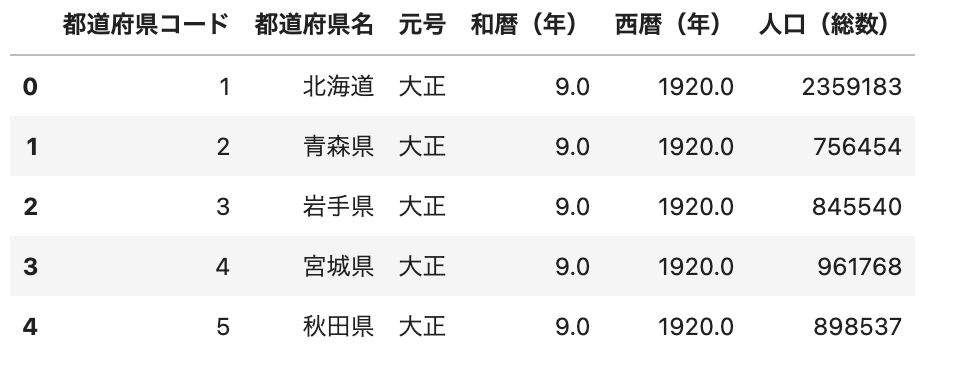
df_5 = df[['都道府県コード', '都道府県名', '元号', '和暦(年)','西暦(年)', '人口(総数)']]
df_5.head()
df_2 = df[['人口(総数)', '人口(男)', '人口(女)']]
df_2.head()
# df_5とdf_2で重複している「人口(総数)」の列をまとめて結合
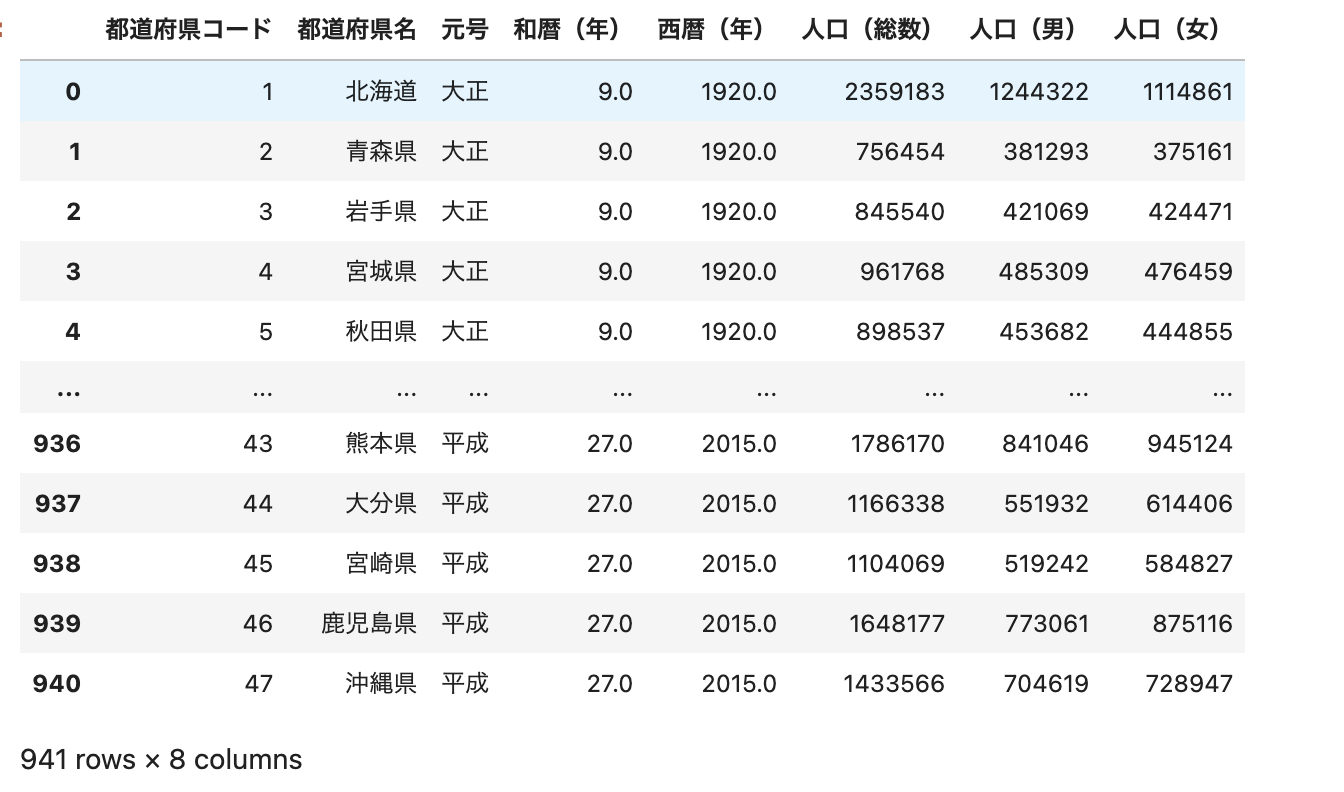
_df = pd.merge(df_5, df_2)
_df
ポイント
pd.merge()関数を使用すると行数が増えることがあります。
今回は939行だったデータから941行に増えています。
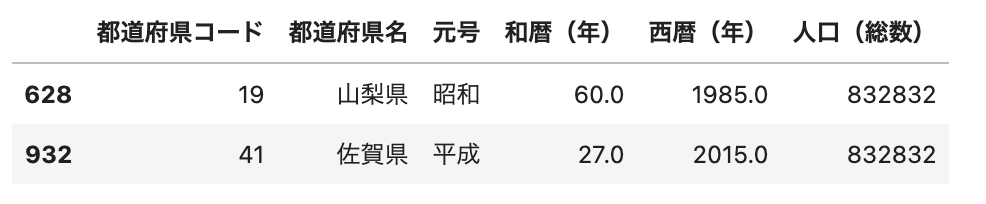
人口(総数)をキーにしてデータを結合していますが、df_5に同じ人口(総数)「832832」が複数含まれていました。
この場合df_2の人口(総数)「832832」に対して、すべてのパターンで結合するためデータ行が増えることになリます。
df_5[df_5['人口(総数)']==832832]
df_2[df_2['人口(総数)']==832832]
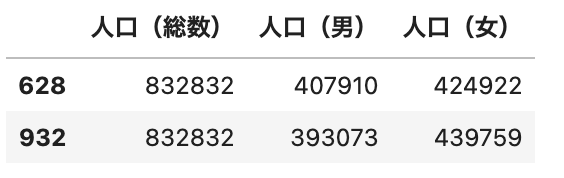
_df[_df['人口(総数)']==832832]
【DataFrameを結合する | join()】
DataFrame.join()はpandas.DataFrameのメソッドのみとなります。- インデックスをキーに結合します。
df_1 = df[['都道府県コード', '都道府県名', '元号', '和暦(年)','西暦(年)']]
df_1.head()
df_2 = df[['人口(総数)', '人口(男)', '人口(女)']]
df_2.head()
df_1.join(df_2)
# pd.concat([df_1, df_2], axis=1)と同じ
ポイント
- 同じ行数のDataFrame同士を結合する場合、重複する列を片方のデータから削除してから
concat()関数もしくはDataFrame.join()で結合する方が良いと思います。 - DataFrameとSeriesを結合する場合は、
concat()関数のみ使用できます。
【おわりに】
今回は「concat」、「merge」、「join」について、それぞれの違いに触れながら紹介しました。
データ形式や使用用途に応じて結合方法を選ぶ必要がありますが、個人的にはpd.concat()関数が万能なのではないかと思います。
今回、使用したCSVファイルやJupyter NotebookはGitHubに公開しています。
Jupyter Notebookは下記コマンドでダウンロードできるので、自由に使って是非練習してみてください。
$ curl https://raw.githubusercontent.com/nakachan-ing/python-references/master/Pandas/pandasでDataFrameを結合する.ipynb -O
python-references/Pandas at master · kyotalab/python-references
Contribute to kyotalab/python-references development by creating an account on GitHub.
github.com
コメント